برخی افراد رونق هوش مصنوعی (AI) را با انقلاب صنعتی مقایسه کرده اند. انقلاب صنعتی، کار یدی را خودکارسازی کرد و هوش مصنوعی می تواند به خودکارسازی بسیاری از وظایف فکری رایج کمک کند. این غیرقابل انکار است که هوش مصنوعی زندگی ما را بهبود می بخشد، از ایجاد دستیارهای دیجیتالی توانمندتر تا وسایل نقلیه خودران. اما در حالی که هوش مصنوعی از بسیاری جهات به ما کمک می کند، چیزی که مردم اغلب نادیده می گیرند این است که چگونه هوش مصنوعی می تواند تعصبات انسانی را نیز تداوم بخشد.
تعصب الگوریتم
یک مثال کلاسیک از سوگیری هوش مصنوعی در COMPAS (نمایه مدیریت جرم اصلاحی برای مجازاتهای جایگزین) یافت میشود، یک ابزار پشتیبانی نرمافزاری که احتمال تکرار یک بِزِه توسط متهم را ارزیابی میکند و برای نشان دادن احتمال بازداشت مجدد یک زندانی پس از آزادی ، یک امتیاز خطر بین 1 تا 10 صادر میکند. به نظر می رسد که الگوریتم هایی که سعی در پیش بینی تکرار جرم دارند می توانند به شدت تحت تأثیر نرخ تاریخی بازداشت قرار گیرند و از آنجایی که آمریکایی های آفریقایی تبار در گذشته به طور ناعادلانه ای برای دستگیری هدف قرار گرفته اند، این الگوریتم ها ممکن است به طور ناعادلانه ای همان جمعیت را هدف قرار دهند.
اما نمونههای نا آشکار بسیاری در این زمینه وجود دارند، مانند این واقعیت که تا همین اواخر توییتر چهرههای مردانه سفیدپوست را به هزینه افراد اقلیت در همان تصویر متمرکز میکرد.این گونه سوگیری ها در هوش مصنوعی به حوزههای مختلفی از جمله مراقبتهای بهداشتی (تشخیصهای دقیق)، اشتغال (کسی که موقعیت شغلی را تصاحب میکند) و امور مالی (شخص وام گیرنده) نیز گسترش مییابند.
نحوه عملکرد تعصبی هوش مصنوعی: یک مثال ساده
برای درک نحوه ورود سوگیری به سیستم های هوش مصنوعی، اجازه دهید یک مثال فرضی ساده از نحوه استفاده هوش مصنوعی از داده ها را در نظر بگیریم. دادههای این مثال بر اساس دادههای واقعی است، اما بیانگر آماری شهرهای نیویورک یا ایلینوی نیست. بیایید فرض کنیم که شخصی بنام جو که صاحب یک رستوران زنجیره ایست در حال افتتاح یک رستوران جدید در شهر نیویورک است و بیشتر مکان های فعلی او در حومه ایلینوی هستند. از آنجایی که اجاره ساختمان در نیویورک گران است، او تصمیم می گیرد مبلغ انعام را در صورتحساب مشتری لحاظ کند و می خواهد در مورد اندازه این مقادیر انعام منصفانه رفتار کند.
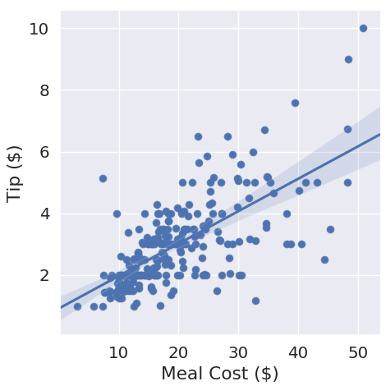
جو تصمیم می گیرد یک متخصص داده استخدام کند تا از داده های میزان انعام رستوران های دیگرش برای تعیین مقدار انعام در نیویورک استفاده کند. آن متخصص قبلاً این کار را برای مشتریان دیگر در نیویورک انجام داده است و به جو توضیح می دهد که این داده ها چگونه هستند. با قرار دادن یک فرمول خطی (y = mx + b) برای داده های انعام که در آن “” y مقدار انعام و “” x هزینه وعده غذایی است، می توانید با استفاده از همان خط سعی کنید میزان انعام در آینده را پیش بینی کنید (” “m شیب خط و “” b محور تقاطع خطی y است). این رگرسیون (بازگشت) خطی نامیده میشود و یکی از سادهترین الگوریتمهای یادگیری ماشینی است، وقتی بحث در مورد هوش مصنوعی باشد معمولاً در مورد یادگیری ماشینی گفته میشود که زیرشاخه هوش مصنوعی است. در این مورد، همانطور که در شکل 1 نشان داده شده است، متخصص داده ها نشان می دهد که یک خط متناسب با داده های انعام جمع آوری شده از رستوران های دیگر در نیویورک، انعام 5.10 دلار را برای یک وعده غذایی با قیمت 40.00 دلار پیش بینی می کند.
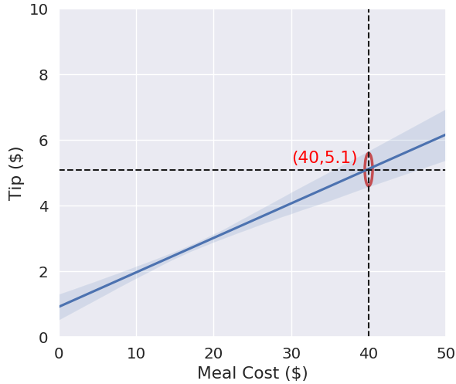
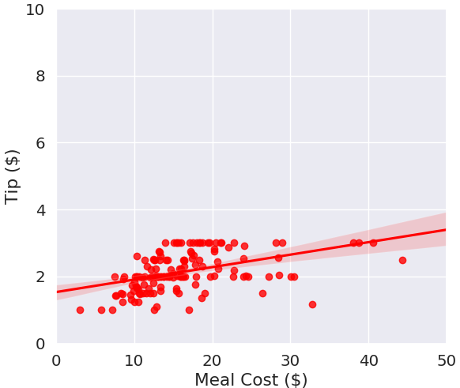
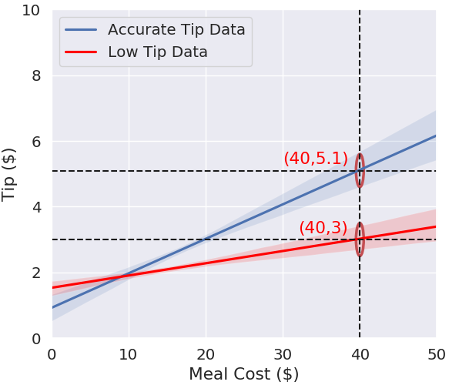
سپس متخصص داده ها از فرآیند مشابهی بر روی داده های جو در مورد انعام حومه ایلینوی استفاده می کند. مشخص میشود که مردم در حومه ایلینوی به اندازه مردم نیویورک انعام نمی داده اند. اگر جو از داده های انعام ایلینوی استفاده کند، سرورهای او برای یک وعده غذایی 40 دلاری به جای انعام 5.10 دلاری، انعام 3 دلاری دریافت خواهند کرد (شکل 2 را ببینید). حتی اگر این میزان برای کارگران او در حومه ایلینوی دستمزدی منصفانه باشد، این انعام کمتر دستمزدی ناعادلانه برای سرورهای جو در نیویورک خواهد بود.
این “تبعیض” و سوگیری علیه پیشخدمت ها در نیویورک از کجا آمده است؟ از داده ها به دست آمده است. همه الگوریتمهای هوش مصنوعی با استفاده از دادهها ساخته میشوند، بنابراین دادههای نادرست یا مغرضانه منجر به مدلهای نادرست یا مغرضانه میشوند. یا همانطور که اغلب گفته می شود، “آشغال به داخل، آشغال خروجی”. در این مورد، داده های انعام از ایلینوی نباید برای محاسبه انعام در نیویورک استفاده شوند، اما همین اصل در مورد هر رشته دیگری، اعم از تشخیص چهره، تعقیب کیفری، سیستم های توصیه کننده یا مراقبت های بهداشتی نیز صدق می کند.
شکل 1: نمونه ای از رگرسیون خطی در داده های فرضی انعام در نیویورک
منبع: Sean Oesch
شکل 2: تفاوت بین مدل بر اساس داده های فرضی انعام ایلینوی (قرمز) و داده های انعام نیویورک (آبی)
منبع: Sean Oesch
رفع سوگیری در هوش مصنوعی بی اهمیت است و سوگیری انسانی را برطرف نمی کند
چندین دلیل وجود دارد که رفع سوگیری در هوش مصنوعی یک مشکل حاد است:
1- گاهی اوقات داده های مورد نیاز برای ایجاد یک سیستم بی طرفانه به سادگی در دسترس نیست، بنابراین در این زمینه محققان با یک معضل اخلاقی مواجه می شوند، که آیا باید از یک مجموعه داده تا حدی مغرضانه استفاده کنند یا اصلاً استفاده نکنند؟
2- شناسایی سوگیری در سیستمهای هوش مصنوعی تا زمانی که نشان داده نشود دشوار است، به ویژه زمانی که الگوریتمها بر روی مجموعه دادههای آنقدر بزرگ آموزش داده میشوند که هیچ انسانی نمیتواند آنها را بهطور موثر برای سوگیری ارزیابی کند. این مشکل در زمینههایی مانند پردازش زبان طبیعی که در آن از متنهای انبوهی که از اینترنت جمع آوری شدهاند برای آموزش مدلها استفاده میشود، آشکارتر است.
3- مدلی که سوگیری کمتری دارد همچنان می تواند توسط انسان های مغرض مورد سوء استفاده قرار گیرد. برای مثال، چین ممکن است از فناوری تشخیص چهره برای هدف قرار دادن و بازداشت جامعه اویغورها در اردوگاههای کار اجباری استفاده کرده باشد. در چنین مواردی، مدلهای بهتر تشخیص چهره به ندرت برای قشر اقلیت سودمند هستند.
4- این مشاهدات منجر به دو سؤال مهم می شود که ارزش بررسی دارند. اول، آیا هوش مصنوعی همیشه راه حل مناسبی است؟ ما فرض میکنیم که باید سوگیری را در هوش مصنوعی برطرف کنیم، اما شاید در وهله اول نباید حجم عظیمی از داده را جمعآوری و استفاده کنیم. هوش مصنوعی ابزار قدرتمندی است و ارزش این را دارد که بدانیم در چه زمانی و چگونه باید از آن استفاده کرد یا اینکه اصلا نباید از آن استفاده کرد. ثانیاً، چگونه به موضوع سوگیری در قلب انسان بپردازیم؟ اولگا روساکوفسکی پروفسور علوم کامپیوتر در پرینستون، خاطرنشان میکند که «بیطرفکردن انسانها سختتر از بیطرفکردن سیستمهای هوش مصنوعی است». و این واقعاً اصل مشکل است: رفع سوگیری در یک الگوریتم به اصلاح سوگیری در جامعه منجر نمیشود.
مسیح راهی برای رسیدگی به تعصب و سوگیری در قلب انسان ارائه می دهد
ساده انگاری است که بگوییم صرفا باور به پیام مسیحیت توسط مردمی که به شکل خدا ساخته شده اند و به همان اندازه به نجات نیاز دارند، تعصب و سوگیری را در قلب انسان برطرف می کند. با کنار گذاشتن موضوع ریاکاری، حتی پیروان متعهد عیسی مسیح نیز با تعصب و سوگیری مبارزه می کنند. یکی از راههای مبارزه با چنین تعصبی این است که عیبهای خود را بپذیریم و به دنبال فروتنی باشیم تا بتوانیم به شکافهای جنسیتی، نژادی، سیاسی و الهیاتی گوش فرا دهیم و به دیگران اجازه دهیم وقتی به بیراهه میرویم ما را سرزنش و اصلاح کنند. Christ offers us this path to address the bias in our own hearts. هیچ راه حل سریعی برای اصلاح تعصب و سوگیری انسان وجود ندارد، اما چیزی که عیسی به ما می دهد، قدرت عشق ورزیدن و یادگیری از کسانی است که با ما متفاوت هستند و این انگیزه ای برای تحقق بخشیدن به آن است.
In May 1997, an IBM chess-playing computer called Deep Blue defeated a grandmaster human chess player (under regular time controls) for the first time...